Encoding
- Receive
-
ホストから送られてくる漢字コード。
使用可能文字コードは文字コードページを参照ください。
- Transmit (Use different code)
-
送出する漢字コード。
使用可能文字コードは文字コードページを参照ください。
Unicode
Unicode(UTF-8)使用時の "Tera Term が描画する文字幅" を設定します。
Tera Term の接続先が意図している文字幅を指定すると、画面崩れが少なくなります。
描画する文字幅に対して Tera Term がフォントをどのように描画するかについては、
描画幅に合わせてリサイズしたフォントを描画
を参照ください。
Ambiguous Characters width
East_Asian_Width プロパティの値が Ambiguous(曖昧) の文字の文字幅を、1 Cell または 2 Cell から選択します。
各プロパティ値については East_Asian_Widthプロパティと文字幅(セル数)について を参照ください。
Override Emoji Characters width
絵文字プロパティが Yes の文字の文字幅を設定します。
このプロパティについては 絵文字の文字幅(セル数)について を参照ください。
チェックしないと、East_Asian_Width プロパティの値に基づいて文字幅が決定されます。
チェックすると、East_Asian_Width プロパティの値(W, N, A)にかかわらず一律に文字幅を設定します。
- コードポイント U+1F000 以上の絵文字は常に 2 Cell (全角) として扱います。
- コードポイント U+1F000 未満の絵文字は
- 2 Cell が選択されたとき
- 2 Cell (全角) として扱う
- 1 Cell が選択されたとき
- 1 Cell (半角) として扱う
文字ごとの文字幅オーバーライド設定を使う
TERATERM.INIに 文字幅設定 が存在すると、チェックボックスが有効になります。
チェックすると、ユーザーの文字幅設定が使用されます。
Tera Term は、Unicodeの仕様や設定に応じて文字幅を決定します。
接続先が、上記の「あるプロパティを持つ文字」より細かく文字幅を分けている場合、
この設定を用いて柔軟に Tera Term の文字幅を設定することができます。
接続先(のプログラム)のUnicodeバージョンが Tera Term と異なっていたり、
独自の文字幅を使用したい場合を想定しています。
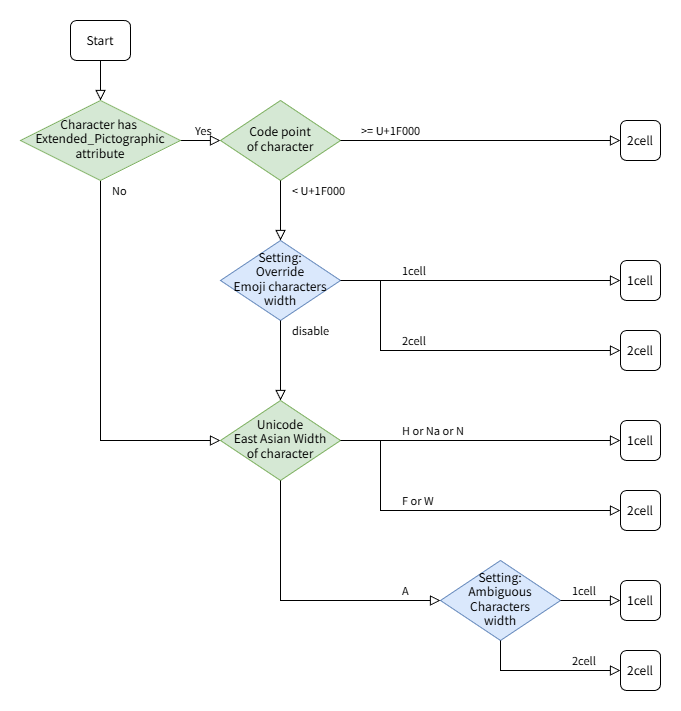
文字幅の決定フロー
ここまでに挙げたように、Tera Term には描画する文字幅を指定する設定が複数あります。
設定の優先順位がどうなっているのか以下に図示します。
DEC Special Graphics
DEC Special Graphics(DEC特殊グラフィック)の
表示方法を指定します。
- UnicodeをDEC Special Graphicsへマッピングする
-
UnicodeをDEC Special Graphicsへ置き換え、"Tera Special" フォントを使用して表示します。
DEC Special Graphicの文字幅は1cell(half-width)となります。
変換する文字種を指定できます。
UnicodeからDEC Special Graphicsへのマッピングを設定するも参照してください
- 罫線素片(U+2500-U+257F)
- Punctuation, Block Elements, Shade
- 中点(U+00B7,U+2024,U+2219)
- DEC Special GraphicsをUnicodeへマッピングする
-
DEC Special GraphicをUnicodeへ置き換え、VTウィンドウのフォントを使用して表示します。
Unicodeで表示する文字の文字幅は、文字毎に異なり
Ambiguous Characters width 設定で変化します。
- DEC Special Graphicsをマッピングしない
-
DEC Special Graphicsは "Tera Special" フォントを使用して表示し、
Unicodeの置き換えは行いません。
Japanese JIS
Receive
- Half-width kana
-
ホストから送られてくる"半角"片仮名コードが 7 bit で表現されている
(SO/SI を用いたシフト制御を用いている)場合に選択してください。
Kanji (receive) が JIS の場合のみ有効です。
Transmit
- Half-width kana transmit
-
送出する"半角"片仮名コードを7bitで表現する
(SO/SI を用いたシフト制御を用いる)場合に選択してください。
Kanji (transmit) が JIS の場合のみ有効です。
- Kanji-in
-
Kanji (transmit) が JIS のときに使用するエスケープシーケンス
(漢字コードを G0 に指示するシーケンス。
^[$@ または ^[$B )。
ホストから送られてくるエスケープシーケンスはどちらでも構いません。
- Kanji-out
-
Kanji (transmit) が JIS のときに使用するエスケープシーケンス
(ASCII または JIS ローマ字コードを G0 に指示するシーケンス。
^[(B または ^[(J )。
ホストから送られてくるエスケープシーケンスはどちらでも構いません。
注意: ^[(H は初期設定では選択できません。
→ ^[(H を選択可能にする。